Học sâu dựa trên mạng nơ-ron nhân tạo (Phần II)
“All the impressive achievements of deep learning amount to just curve fitting.”
“Tất cả các thành tựu ấn tượng của học sâu thực chất chỉ là khớp đường cong.”
― Judea Pearl
Giới thiệu | Phần I | Phần III
Theo các giáo sư LeCun, Bengio và Hinton, “Học sâu (Deep learning) cho phép các mô hình tính toán gồm nhiều tầng xử lý để học biểu diễn dữ liệu với nhiều mức trừu tượng khác nhau” [9]. Chúng tôi chỉ tập trung vào học sâu dựa trên mạng nơ-ron nhân tạo (Artificial Neural Networks) – mô hình học lấy ý tưởng từ hệ thống kết nối các tế bào thần kinh trong bộ não người.
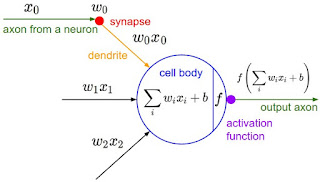
Thật vậy, trong bộ não người, tế bào thần kinh là đơn vị tính toán cơ bản. Phần bên trái của Hình 3 mô tả một tế bào thần kinh sinh học, bao gồm các thành phần chính là thân tế bào (cell body), trục (axon), sợ nhánh (dendrite) và khớp (synapse) hay “axon terminals” như trong hình. Bộ não người chứa khoảng 86 tỉ tế bào thần kinh [2], 10^14-10^15 khớp thần kinh. Các khớp có vai trò nối một tế bào thần kinh này với các tế bào thần kinh khác thông qua các sợi nhánh. Phần bên phải của Hình 3 mô tả một tế bào thần kinh nhân tạo. Thân tế bào thần kinh nhân tạo, từ đây sẽ gọi tắt là nơ-ron, gồm có phần tính tổng có trọng số (weighted sum) các đầu vào và hàm kích hoạt (activation function) f chuyển đổi kết quả tổng tính được thành đầu vào cho các nơ-ron khác.
Theo các giáo sư LeCun, Bengio và Hinton, “Học sâu (Deep learning) cho phép các mô hình tính toán gồm nhiều tầng xử lý để học biểu diễn dữ liệu với nhiều mức trừu tượng khác nhau” [9]. Chúng tôi chỉ tập trung vào học sâu dựa trên mạng nơ-ron nhân tạo (Artificial Neural Networks) – mô hình học lấy ý tưởng từ hệ thống kết nối các tế bào thần kinh trong bộ não người.
Thật vậy, trong bộ não người, tế bào thần kinh là đơn vị tính toán cơ bản. Phần bên trái của Hình 3 mô tả một tế bào thần kinh sinh học, bao gồm các thành phần chính là thân tế bào (cell body), trục (axon), sợ nhánh (dendrite) và khớp (synapse) hay “axon terminals” như trong hình. Bộ não người chứa khoảng 86 tỉ tế bào thần kinh [2], 10^14-10^15 khớp thần kinh. Các khớp có vai trò nối một tế bào thần kinh này với các tế bào thần kinh khác thông qua các sợi nhánh. Phần bên phải của Hình 3 mô tả một tế bào thần kinh nhân tạo. Thân tế bào thần kinh nhân tạo, từ đây sẽ gọi tắt là nơ-ron, gồm có phần tính tổng có trọng số (weighted sum) các đầu vào và hàm kích hoạt (activation function) f chuyển đổi kết quả tổng tính được thành đầu vào cho các nơ-ron khác.
 |  |
|---|---|
| Nguồn: Internet | Nguồn: Luận án tiến sĩ của Andrej Karpathy |
| Hình 3: Tế bào thần kinh sinh học (trái) và nơ-ron trong mạng nơ-ron nhân tạo (phải) |
Mô hình tính toán của mạng nơ-ron nhân tạo được phát minh vào năm 1943 bởi nhà vật lý sinh học thần kinh (neurophysiologist) Warren McCulloch và nhà logic học Walter Pitts [3]. Năm 1958, nhà tâm lý học Rosenblatt [4] tạo ra mô hình học nơ-ron nhân tạo đầu tiên, gọi là perceptron, chỉ có một nơ-ron. Năm 1986, Rumelhart, Hinton và Williams phát minh ra giải thuật lan truyền ngược dùng để tính toán đạo hàm dựa trên hàm mất mát (loss function) góp phần huấn luyện thành công mạng nơ-ron nhân tạo [5]. Năm 1989, Yann LeCun ứng dụng thành công giải thuật lan truyền ngược vào mạng nơ-ron tích chập (Convolutional Neural Networks – CNN) [6]. Năm 1997, mạng nhớ ngắn-dài hạn (Long Short-Term Memory -LSTM) được phát minh bởi Hochreiter và Schmidhuber [7] nhằm giải quyết vấn đề đạo hàm suy giảm về zê-rô (vanishing) của mạng nơ-ron hồi qui (Recurrent Neural Networks – RNN).
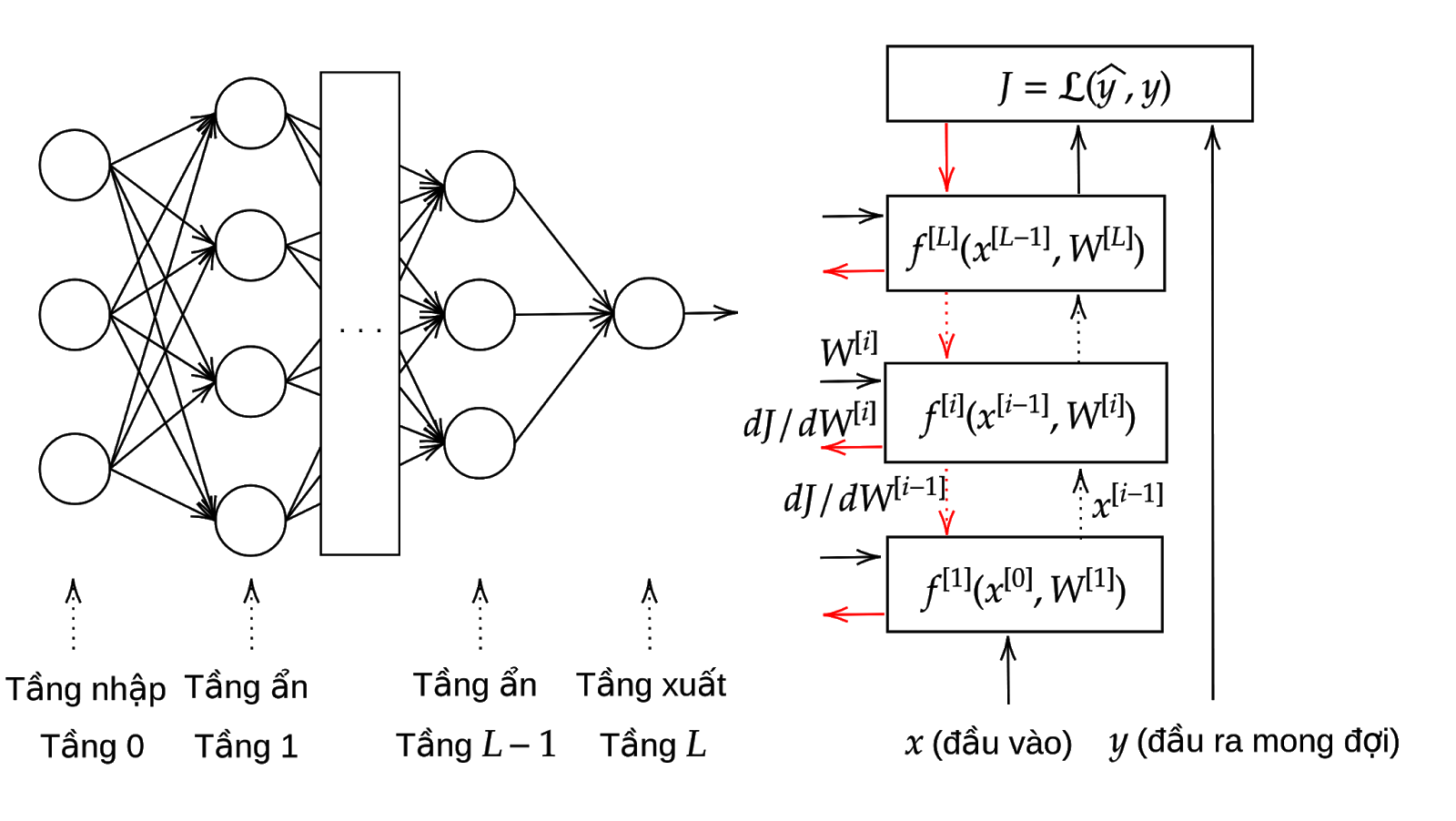 Hình 4: Một ví dụ về mạng nơ-ron nhân tạo nhiều tầng
Hình 4: Một ví dụ về mạng nơ-ron nhân tạo nhiều tầng
Hình 5: Một ví dụ về mô hình học sâu dựa trên mạng nơ-ron[8]
 Hình 6: Chia sẻ tham số của mạng nơ-ron tích chập, trong đó w1=w4=w7, w2=w5=w8, w3=w6=w9
Hình 6: Chia sẻ tham số của mạng nơ-ron tích chập, trong đó w1=w4=w7, w2=w5=w8, w3=w6=w9
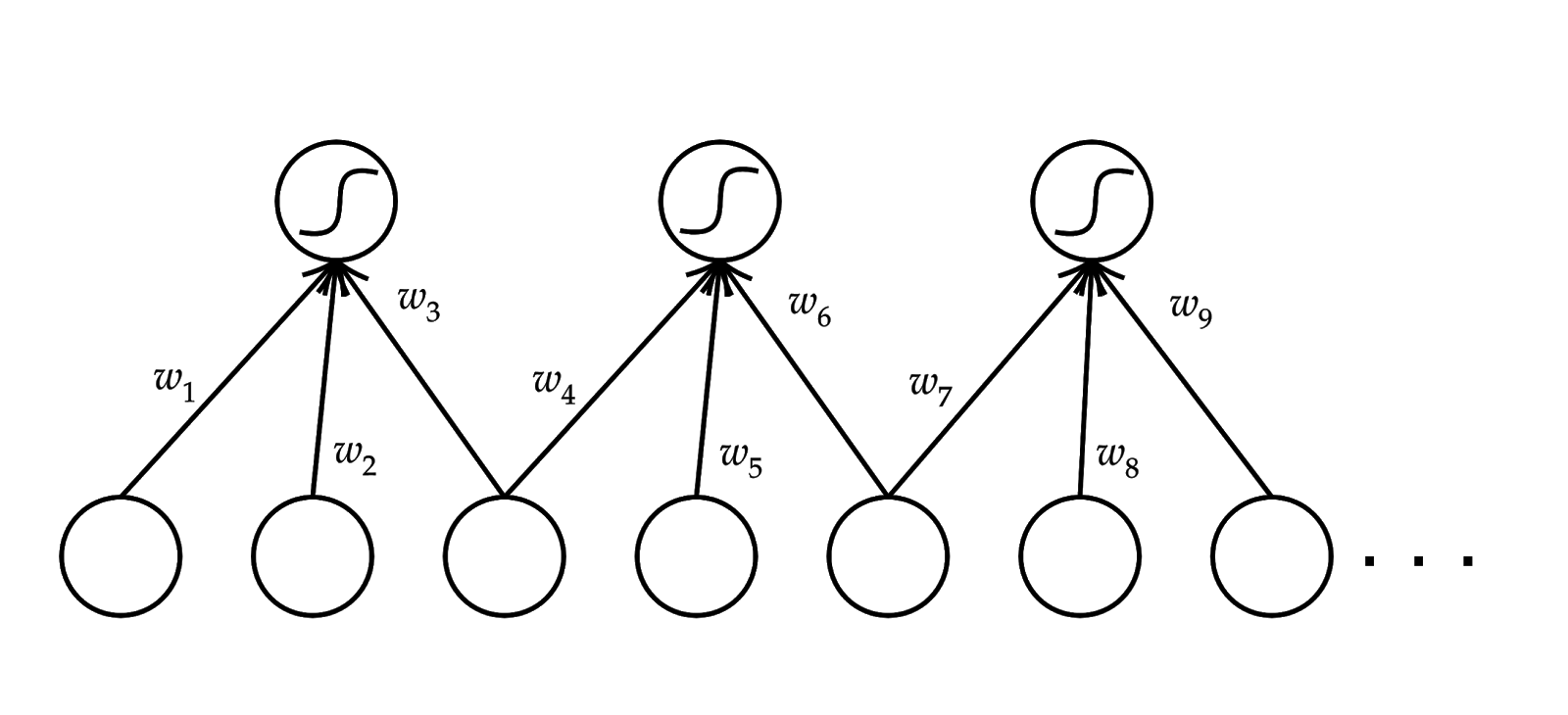 Hình 6: Chia sẻ tham số của mạng nơ-ron tích chập, trong đó w1=w4=w7, w2=w5=w8, w3=w6=w9
Hình 6: Chia sẻ tham số của mạng nơ-ron tích chập, trong đó w1=w4=w7, w2=w5=w8, w3=w6=w9Phần bên trái Hình 4 cho thấy một mạng nơ-ron gồm nhiều tầng, trong đó nơ-ron của tầng trước kết nối đầy đủ (fully-connected) với các nơ-ron của tầng sau. Mạng nơ-ron dạng này là mạng nơ-ron truyền thẳng (Feed-forward Neural Networks – FNN) hay mạng perceptron nhiều tầng (Multilayer Perceptron – MLP). Phần bên phải của Hình 4 mô tả cơ chế lan truyền ngược để tính đạo hàm của hàm chi phí (hàm J) theo tham số ở từng tầng của mô hình. Hình 5 mô tả một ví dụ về mạng nơ-ron tích chập. Mạng gồm hai phần: phần tích chập (convolutional layers) và truyền thẳng (fully-connected layers). Phần tích chập rút trích tự động đặc trưng của dữ liệu đầu vào, tầng càng nhỏ thì học các đặc trưng thô (mức thấp), tầng càng sâu thì học đặc trưng càng chi tiết (mức cao) của khái niệm cần học. Ví dụ trong Hình 5 cho thấy tầng đầu học các đặc trưng cạnh (edge), các tầng kế tiếp học được đặc trưng các thành phần, rồi đến đặc trưng chi tiết của đối tượng học. Hình 6 mô tả khả năng chia sẻ tham số của mạng CNN, góp phần giảm số lượng tham số cần phải học.
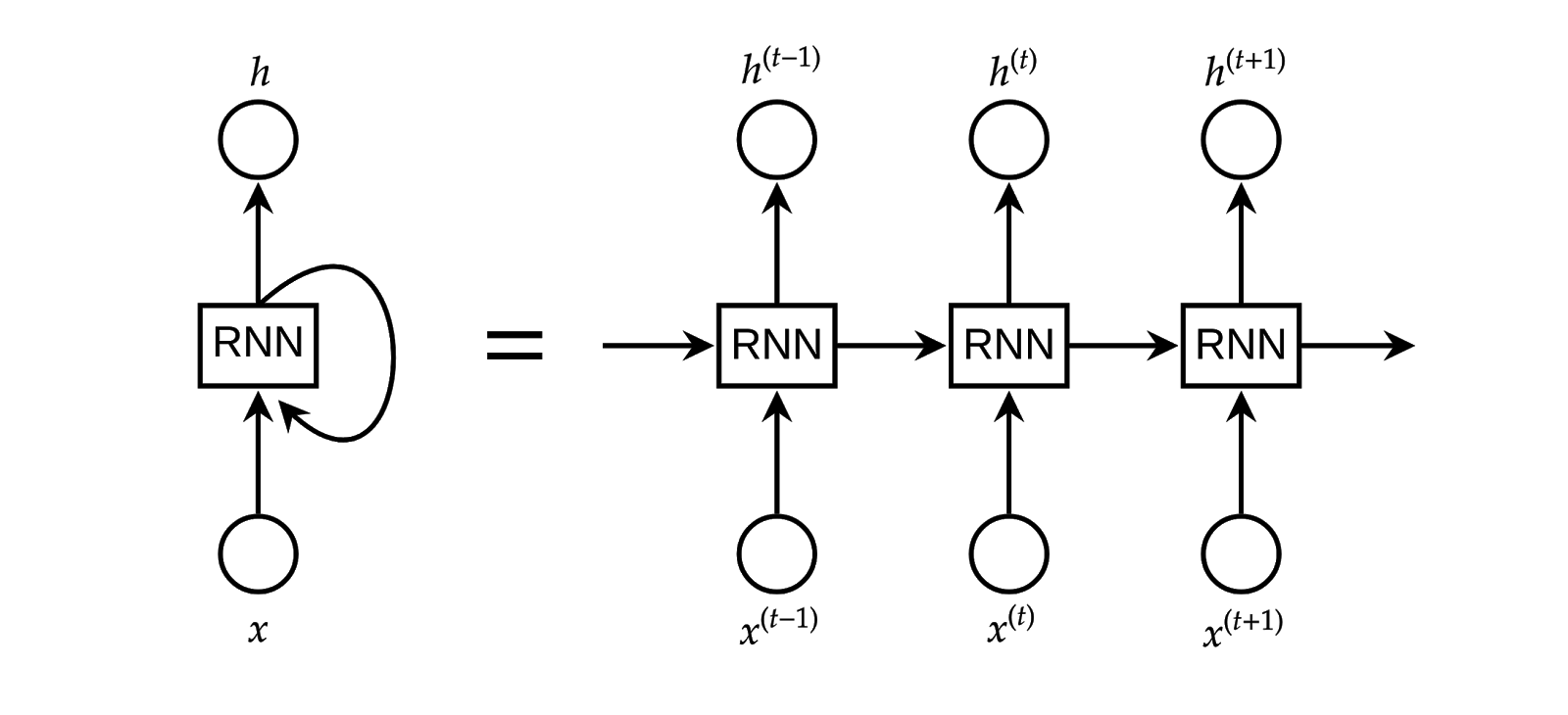 Hình 7: Mạng nơ-ron hồi qui
Hình 7: Mạng nơ-ron hồi qui Hình 8: Các loại mạng nơ-ron hồi qui
Hình 8: Các loại mạng nơ-ron hồi qui
Hình 9: Mạng LSTM
Hình 7 mô tả mô hình mạn nơ-ron hồi qui. Qua hình chúng ta thấy mỗi nơ-ron tại một tầng của mạng nơ-ron hồi qui (trừ tầng đầu) đều nhận vào hai loại đầu vào: dữ liệu nhập và đầu ra của tầng trước. Hình 8 mô tả các loại mạng nơ-ron hồi qui, trong đó (a) là mạng một đầu vào một đầu ra (ví dụ: phân loại ảnh, đầu vào là một tấm ảnh, đầu ra là một loại), (b) là mạng một đầu vào nhiều đầu ra (ví dụ: chú thích ảnh, đầu vào là một tấm ảnh, đầu ra là một dòng chú thích), (c) là mạng nhiều đầu vào một đầu ra (ví dụ: phân tích quan điểm, đầu vào là một dòng văn bản, đầu ra là quan điểm khen hay chê), (d) là loại mạng nhiều đầu vào nhiều đầu ra (ví dụ: dịch máy tự động, đầu vào là một câu của ngôn ngữ này, đầu ra là một câu của ngôn ngữ khác) và (e) cũng là loại mạng nhiều đầu vào nhiều đầu ra nhưng hình dạng khác (ví dụ: phân loại video, khi ta muốn gán nhãn cho mỗi frame của video đầu vào; hoặc gán nhãn từ loại). Hình 9 là mô hình mạng Long Short-Term Memory. Mỗi khối gồm có ba cổng, đánh dấu bằng kí hiệu ⊗, tính từ trái qua phải, kí hiệu ⊗ đầu tiên đại diện cho cổng quên (forget gate), kí hiệu ⊗ thứ hai đại diện cho cổng nhập (input gate) và kí hiệu ⊗ thứ ba đại diện cho cổng xuất (output gate). Vai trò chi tiết của mỗi cổng sẽ được nói trong bài giảng về LSTM.
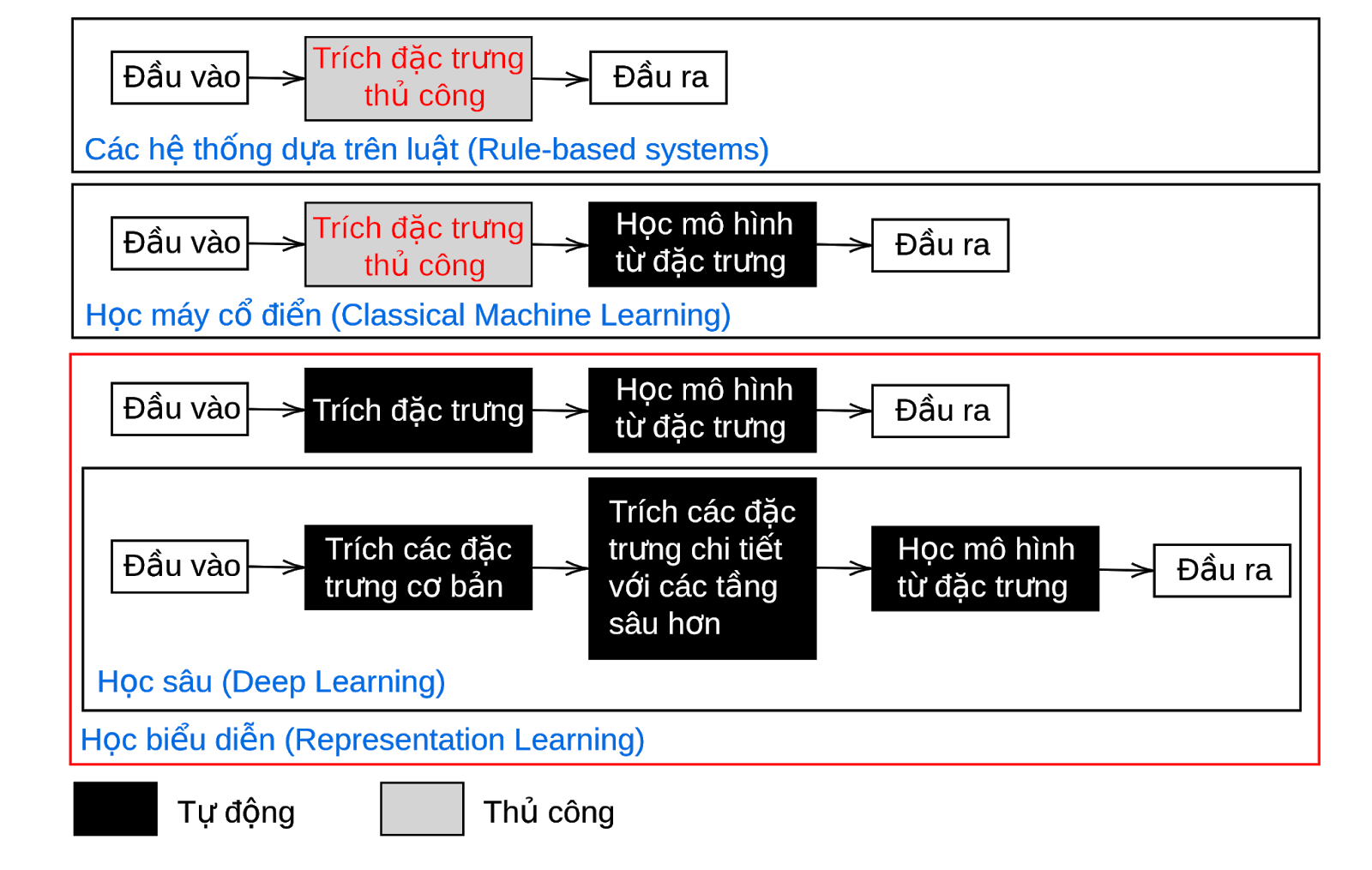 Hình 10: Học sâu trong tương quan với các mô hình học khác
Hình 10: Học sâu trong tương quan với các mô hình học khácHình 10 cho thấy sự tương quan giữa học sâu với các hệ thống học cổ điển và dựa trên luật. Với các hệ thống học dựa trên luật thì các luật và đặc trưng được rút trích thủ công. Với các hệ thống học cổ điển, ví dụ như học cây quyết định, các đặc trưng được trích thủ công, mô hình học là tự động. Học sâu được xem là một phần của học biểu diễn (representation learning) với đặc trưng và mô hình học đều tự động, nhưng các đặc trưng được học bằng nhiều tầng học khác nhau.
Tất cả các mô hình học nêu trên như FNN, CNN, RNN, LSTM đều là các thành phần cơ bản của các mô hình học sâu đột phá gần đây. Tuy vậy, học sâu tiêu tốn rất nhiều nguồn lực tính toán. Nhóm nghiên cứu của Facebook [9] huấn luyện mô hình với tập huấn luyện ImageNet-1k mất một giờ và sử dụng đến 256 GPU. Trong khi bộ não người có khoảng 86 tỉ tế bào thần kinh và thực hiện khoảng 10^16 phép tính trên một giây, GPU NVIDIA Tesla P100 giá 6 nghìn USD (tháng 7 năm 2018) thực hiện được 21×10^12 phép tính trên một giây. Trong gần 50 năm qua, năng lực tính toán của máy tính tuân theo định luật More – phát biểu rằng cứ sau mỗi hai năm thì năng lực tính toán của các bộ vi xử lý tăng gấp đôi và giá thành giảm một nữa – nhưng với quãng thời gian gần 50 năm một con GPU được xem là tương đối mạnh với giá thành 6 nghìn USD chỉ mới đạt khoảng 1/10.000 năng lực tính toán của bộ não người. Vì vậy các xu hương mới nhằm tạo đột phá trong trí tuệ nhân tạo là đầu tư nghiên cứu các nguyên tắc của việc học và trí tuệ của con người. Một xu hướng nữa là phát triển phần cứng có năng lực tính toán vượt trội, không tuân theo định luật More, với các hướng tìm năng là điện toán lượng tử (quantum computing) và điện toán mô phỏng não người (neuromorphic computing).
Tài liệu tham khảo
[1]Yann LeCun, Yoshua Bengio, Geoffrey Hinton. Deep Learning. Nature, Tập 521, trang 436–444 (2015).
[2]S. Herculano-Houzel. The Human Brain in Numbers: A Linearly Scaled-up Primate Brain. Frontiers in Human Neuroscience, 3:31 (2009).
[3]Warren McCulloch và Walter Pitts. A Logical Calculus of Ideas Immanent in Nervous Activity. Bulletin of Mathematical Biophysics. 5 (4): 115–133 (1943).
[4]F. Rosenblatt. The Perceptron: A Probabilistic Model For Information Storage And Organization In The Brain. Psychological Review. 65 (6): 386–408 (1958).
[5]David Rumelhart, Geoffrey Hinton, Ronald Williams. Learning representations by back-propagating errors. Nature, 323 (6088): 533–536 (1986).
[6]LeCun et al. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Computation, 1, pp. 541–551 (1989).
[7]Sepp Hochreiter và Jürgen Schmidhuber. Long Short-Term Memory. Neural Computation, 9 (8): 1735–1780 (1997).
[8]Wei Yu, Kuiyuan Yang, Yalong Bai, Yong Rui.
Visualizing and comparing convolutional neural networks. ICRL (2015).
Visualizing and comparing convolutional neural networks. ICRL (2015).
[9]Goyal, Priya, et al. “Accurate, large minibatch SGD: training imagenet in 1 hour.” arXiv preprint arXiv:1706.02677
(2017).
(2017).